-
Latent variable model (GAN, Diffusion model)CS 공부/AI 2023. 3. 24. 19:01
Maximum Likelihood Learning
훈련 세트가 주어지면, 우리는 generative model 학습 과정을 모델 계열에서 가장 근사적인 밀도 모델을 찾는 것으로 생각할 수 있다
그렇다면 approximation이 우수하다는 것을 어떻게 측정할까?
KL-divergence (쿨백-라이블러 발산)
- 두 확률 분포 사이의 거리 (근사적으로,,엄밀히는 아님)
- 두 분포의 차이: p와 q의 cross entropy에서 p의 엔트로피를 뺀 값
- 거리의 개념은 아님- 두 확률분포 사이의 거리라면 p-q 사이의 거리나 q-p 사이의 거리나 같아야 함
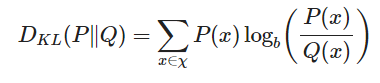


KL-divergence - KL-divergence를 최소화하는 것은 likelihood를 최대화하는 것과 같다 -> likelihood를 최대화하는 방향으로 학습하기!
- 경험적 log-likelihood를 사용하여 예상 log-likelihood(가능도)를 근사화하면 다음과 같다
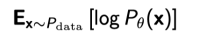
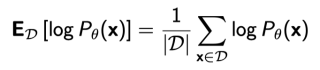
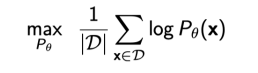
차례대로 가능도 - emperical 가능도 - maximum likelihood learning - 단점: 데이터의 숫자가 적으면 정확하지 않음 (몬테카를로 추정치의 분산이 높음)
Empirical Risk Minimization (경험적 위험도 최소화)
- Maximum Likelihood Learning에 자주 쓰임
- 한정된 데이터로 최적화하기 때문에 overfitting 일어남 (모델이 train 데이터를 기억)
- 이를 해결하기 위해 일반적으로 분포의 hypothesis spce(가설 공간)을 제한
- 각각의 모델의 성능을 한계 짓는 것이기 때문에 전체 모델의 generation 떨어질 수 있음
유사도를 측정하는 다른 방법들은 뭐가 있을까?
- KL-divergence로 maximum likelihood learning or Variational Autoencoder (VAE).
- Jensen-Shannon divergence로 Generative Adversarial Network (GAN).
- Wasserstein distance로 Wasserstein Autoencoder (WAE) or Adversarial Autoencoder
Latent Variable Models
Autoencoder
- Encoder와 Decoder 두 파트로 구성됨
- Encoder: 정보 압축
- Decoder: 정보 복원
- 어떤 입력에 대해서 특징을 추출하여 입력의 압축된 정보를 Latent variables에 담고,
- 이 Latent variables로부터 다시 자기 자신(입력)을 복호화 하는 알고리즘
Variational Autoencoder (VAE)
- autoencoder는 생성모델이 아니지만 VAE는 생성모델이다
- p✓(x)를 최대화하는 방향으로
- Variational inference(VI)의 목표: posterior 분포와 가장 잘 일치하는 variational 분포를 최적화하는 것
- posterior 분포: 계산할 수도 없음
- variational 분포: 계산은 되는데 표현력이 떨어짐
- Maximum Likelhood learning을 최대화하기 위해서는 ELBO를 최대화, Variational Gap을 최소화해야함
- ELBO(Evidence of Lower Bound): KL Divergence를 최소화 하기 위해 사용된다
- ELBO는 계산할 수 있는 값들이다
- VI는 ELBO를 최대화하여 목표를 최소화한다 (계산할 수 없음)
ELBO (Evidence Lower Bound)
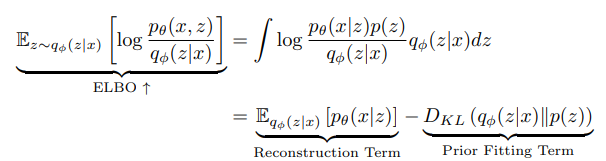
- Reconstruction Term: auto-encoder의 reconstruction loss 최소화함
- 주어진 x로부터 latent space(잠재 공간)에서 sampling된 z가 있을 때, z로부터 x가 발생할 확률
- 즉 z로부터 x가 나타날 확률을 최대화 하는 것(Maximum likelihood estimation)
- Prior fitting term: 잠재 분포가 이전 분포(인코더를 통과해서 나오는 z들의 분포)와 유사하도록 강제한다.
- 단점
- 근사를 통해 최적화하기 때문에 여기에서의 encoder, decoder는 확률 분포라고 보기 어려움
- prior fitting term이 미분가능해야 하는데 그러기 힘듦. 따라서 다양한 latent prior 분포를 사용하기 어려움
- 그래서 보통 prior fitting term에 대해 Gaussian을 사용
GAN (Generative Adversarial Networks)
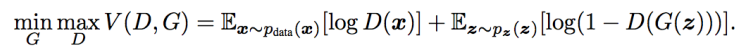
D와 G는 서로 적대적이다. D는 G를 멀리하려고 하고 G는 D를 속이려고함 - Generator는 최대한 실제처럼 보이는 데이터를 생성함으로써 Discriminator를 속이려고 시도하고, 이에 반해 Discriminator는 실제 데이터와 만들어진 가짜 데이터를 구별하려고 노력
- G를 최소화, D를 최대화
- Discriminator: D(x)를 최대한 1에 가깝게 만들고, D(G(z))를 최대한 0에 가깝게 만듦으로써 objective function을 최대화 하는 것이 목적
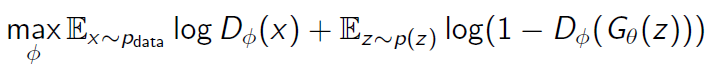
x는 실제 데이터 z는 가짜 데이터 - Generator: )를 최대한 1에 가깝게 만듦으로써, objective function을 최소화하는 것이 목적
- discriminator가 가짜 데이터를 1로 분류하도록 속일 수 있는, 최대한 실제 데이터와 가까운 가짜 데이터를 만드는 방향으로 generator를 학습하는 것

- GAN 학습 과정
- 훈련 데이터를 가지고 Discriminator를 학습시킨다. 이를 통해, 훈련 데이터의 분포를 얻게 된다.
- Latent sample를 통해 노이즈한 값을 Generator에 주고, 생성기에서는 이미지를 생성한다. 분포가 점점 훈련데이터 분포에 따라갈수록 진짜 이미지와 비슷한 이미지를 생성한다.
- 생성된 이미지(가짜 데이터)는 Discriminator에서 가짜 데이터와 진짜 데이터를 구별하게 되고, 오차 역전파를 통해 Generator를 좀 더 진짜 데이터로 만들 수 있는 방향으로 학습하게 된다.
Diffusion Models
- noise로부터 점진적으로 diffusion model를 생성한다
- 장점
- 비효율적, 구현하기 어렵지만 잘 구현했을 때 생성되는 이미지 퀄리티가 매우 좋음
- 특정 영역에 대해서만 이미지를 수정할 수 있음 (주변 배경과 어울리게)
- Forward(diffunsion) process: 이미지를 노이즈화 시키는 과정
- Reverse process: 학습하는 부분, 노이즈를 없애고 이미지를 복원하는 과정
'CS 공부 > AI' 카테고리의 다른 글
Annotation data efficient learning (0) 2023.03.28 AlexNet과 VGGNet (feat. CNN) (0) 2023.03.28 Auto-regressive model (0) 2023.03.23 Multi Head-attention 구조 파악하기 (0) 2023.03.22 Transformer (0) 2023.03.22