CS 공부/AI
AlexNet과 VGGNet (feat. CNN)
imsmile2000
2023. 3. 28. 18:27
Computer Vision이란?
- 전체 지식 중 75%는 눈을 통해 들어온다
- 카메라를 통해 어떤 물체를 포착하면 GPU에 올리고 알고리즘을 사용해 정보를 뽑아냄
- Inverse Rendering 과정
- Visual perception의 종류
- color perception
- motion perception
- 3D perception
- semantic-level perception
- emotion perception
- visuomotor perception 등
Image Classification
1. 모든 분류 문제는 k-NN 알고리즘으로 해결할 수 있다
- k Nearest Neighors 알고리즘: 주변의 가장 가까운 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘
- 하지만 세상의 모든 데이터를 다 가지고 있을 수는 없다,, (시스템 복잡도..메모리...시간 문제..)
2. CNN을 사용해서 방대한 데이터를 제한된 복잡도의 시스템에 압축해서 넣기
- single fully connected layer의 문제
- Layer가 한 층이라 단순해서 평균 이미지 이외에는 표현이 안됨
- single fully connected layer의 문제: 테스트할 때 조금이라도 영상/이미지의 위치나 크기가 안맞으면 정확도 떨어짐
- 모든 픽셀마다 parameter 필요 (엄청나게 많음)
- locally connected neural networks
- 영역을 나눠 특정 노드가 담당한 그 영역의 이미지에 대한 패턴만을 찾아 필요한 parameter가 엄청 줄어듦
- 따라서 Overfitting 방지할 수 있음
- 따라서 CNN은 많은 CV task의 backbone 네트워크로 쓰인다 (image recognition, object detection, segmentation)
CNN을 사용한 Image Classification의 역사
AlexNet
- LeNet-5 (1998)
- 아주 간단한 CNN 구조
- 구조: Conv-Pool-Conv-Pool-FC-FC
- 우편번호 인식에 크게 성공
- LeNet-5 발전 버전
- 7 hidden layers
- ImageNet으로 학습 (1.2millions 데이터)
- ReLU, dropout 사용
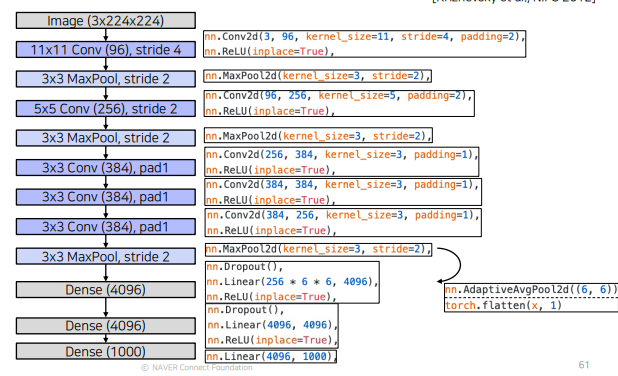
- AlexNet의 구조
- Convolution layer의 output tensor 사이즈
- input image size=I, K*K Conv, stride=S, padding=P일때
- Convolution layer의 output tensor 사이즈


지금은 사라진 것들...
- Local Response Normalization: 측면 억제를 위한 Layer
- 큰 양수의 수가 Conv Layer or MaxPooling시 들어오게 된다면 하나의 큰 값이 주변에 값에 영향을 미치기 때문에 사용 => 지금은 batch normalization 사용
- 큰 filter size (11x11 convolution layer)
- CNN의 Receptive field(수용영역)
- receptive field 안에서는 중앙에 있는 pixel 일수록 더 중요
- kernel size가 늘어나면 늘어날 수록 CNN이 볼 수 있는 영역이 늘어남
- stride=1인 K*K conv, P*P pooling layer가 있다고 하면 pooling layer의 각 단위 값=(P+K-1)*(P+K-1)
VGGNet
- AlexNet보다 더 깊고 간단한 architecture을 가졌지만 더 높은 성능과 일반화 기능을 가짐
- Input: 224*224 (RGB 이미지), AlexNet과 같음
- 가장 큰 특징: stride=1인 3x3 convolution filter과 2x2 max pooling 계산
- 몇개의 큰 conv filter을 쓰는 것보다 여러개의 3x3 conv filter 쓰는 것이 parameter 개수도 적고 더 깊고 receptive field를 크게 유지시킴
- 그외, 3 FC layers, LRN 미사용, ReLU 사용의 특징이 있음