CS 공부/AI
[Segmentation] DeepLab v2~v3+, PSPNet
imsmile2000
2023. 6. 8. 01:10
DeepLab v2
- backbone이 VGG-16에서 ResNet-101로 변경됨


- conv1 block : 7x7 conv - BatchNorm - ReLU - MaxPool
- conv2~conv5: 채널 수를 맞추기 위해 1x1 Conv 추가 (64 ➞ 256, 128 ➞ 512, 256 ➞ 1024, 512 ➞ 2048)
- conv3 block의 첫번째 sub-block에서 stride=2를 이용한 down-sampling 수행 (128x128 -> 64x64), stride=2 1x1 Conv 추가
- conv4,5 block에서 dilated convolution 사용 (down-sampling x)
PSPNet
도입 배경
- Mismatched Relationship: 기존의 FCN은 보트랑 차의 외관이 비슷하다고 boat를 car로 예측
- Confusion Categories: 기존의 FCN은 비슷한 카테고리 혼돈
- Inconspicuous classes: FCN은 배게를 침대 시트로 예측, 두개가 같은 무늬를 가지고 있어서 헷갈려함
- FCN도 Maxpooling을 통해 receptive field를 늘렸지만 왜 잘 예측을 못할까?
Architecture
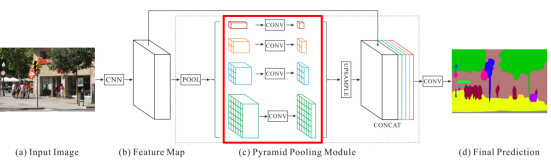
- Global Average Pooling: 주변 정보를 파악해서 객체를 예측하는데 사용(피처맵 전부를 평균내서 대표하는 값을 만듦)
- Average Pooling: 4x4인 feature map이 있으면 2x2 네개로 분할해서 각각의 영역을 대표하는 하나의 값으로 추출
- Feature map에 Average Pooling을 적용해 sub-region을 생성
- 1x1, 2x2, 3x3, 6x6 출력의 average pooling 적용
- sub-region 각각에 Conv 진행하여 채널이 1인 feature map 생성
- 1x1x1, 2x2x1, 3x3x1, 6x6x1
- Feature map과 Pyramid Pooling 모듈을 upsampling한 output을 concat함
DeepLab v3, DeepLab v3+
DeepLab v3 Architecture

DeepLab v3+ Architecture

- Encoder에서 spatial dimension의 축소로 인해 손실된 정보를 Decoder에서 점진적으로 복원
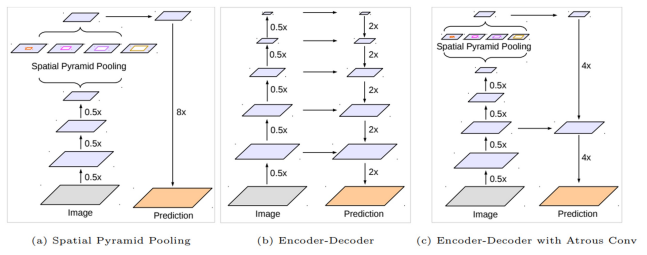
- Encoder
- 수정된 Xception을 backbone으로 사용
- Atrous separable convolution을 적용한 ASPP 모듈 사용
- Backbone 내 low-level feature와 ASPP 모듈 출력을 모두 decoder에 전달
- Decoder
- ASPP 모듈의 출력을 upsampling하여 low-level feature와 결합
- 결합된 정보는 conv 연산 및 upsampling 되어 최종 결과 도출
- 기존의 단순한 upsampling 연산을 개선시켜 디테일 유지
- Encoder
- 수정된 Xception을 backbone으로 사용
- Atrous separable convolution을 적용한 ASPP 모듈 사용
- Backbone 내 low-level feature와 ASPP 모듈 출력을 모두 decoder에 전달
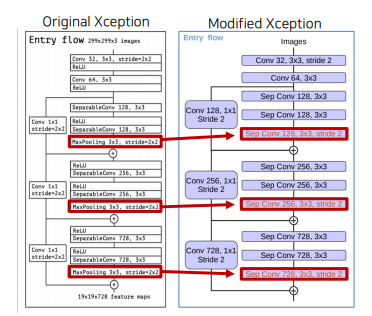
- modified Xception backbone (Encoder DCNN 부분)
- Depthwise Convolution을 사용한 네트워크 (각 채널마다 다른 filter을 사용하여 conv 연산 후 결합)
- Pointwise Convolution =1x1 Convolution
- Depthwise Conv + Pointwise Conv = Depthwise Separable Convolution
- Entry Flow: Max Pooling을 Depthwise Separable Conv + BatchNorm + ReLU로 변경
- Entry Flow 내 첫번째 block 출력을 디코더로 전달 (128x128)
- Middle Flow: 더 깊은 구조 사용 repeat 8 -> repeat 16
- Exit Flow: Max Pooling을 Depthwise Separable Conv + BatchNorm + ReLU로 변경 + Depthwise Separable Conv연산 추가
- Xception 구조를 classification문제에 사용하면 입력을 1/32로 줄이고, segmentation에 사용하면 1/16로 줄임

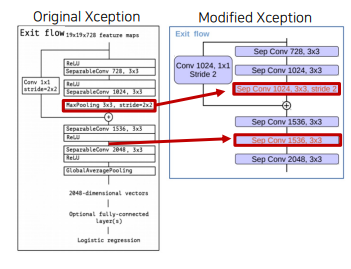
- ASPP (Encoder DCNN 다음 부분)
- bilinear interpolation을 통해 spatial dimension을 다른 출력들과 동일하게 맞춰줌
- 각 결과를 채널 방향으로 쌓아 1x1 conv 연산 수행 후 디코더로 전달 (64x64)
Entry Flow 내 첫번째 block 출력과 ASPP 출력을 bilinear interpolatoin upsampling한 결과를 concat하고 Conv 연산 후 bilinear interpolatoin upsampling하여 최종 결과 도출