-
LoggingCS 공부/Backend 2023. 7. 6. 18:07
데이터의 종류
데이터베이스 데이터(서비스 로그)
- DB에 저장
- 서비스가 운영되기 위해 필요한 데이터 (언제 가입했는지, 어떤 물건 구입했는지)
사용자 행동 데이터(유저 행동 로그)
- Object storage, 데이터 웨어하우스에 저장
- 데이터 분석시 필요한 데이터
- 웹, 앱에서 유저가 어떤 행동을 하는지 나타내는 데이터 (click, view, swipe 등)
인프라 데이터 (metric)
- 백엔드 웹 서버가 제대로 동작하고 있는지 확인하는 데이터
- request 수, response 수, DB 부하 등
Metric: 값을 측정할 때 사용 (cpu, memory)
Log: 운영 관점 데이터 남길 때 (함수 호출, 예외 처리)
Trace: 개발 관점 데이터 (예외 trace)
데이터 적재 방식
Database(RDB)에 저장하는 방식
- 웹, 앱 서비스에서 사용되는 경우 활용
- 실제 서비스용 DB
- 행과 열로 구성, 데이터의 관계 정의하고 모델링 진행
- MySQL, PostgreSQL 등
Database(NoSQL)에 저장하는 방식
- elasticsearch, logstash, fluent, kibana에서 활용하려는 경우
- Not Only SQL
- 데이터가 많아지며 RDBMS로 트래픽 감당하기 어려워서 개발됨 (RDBMS보다 빠름)
- JSON 형태와 비슷하며, XML 등도 활용됨
- MongoDB
Object Storage에 저장하는 방식
- 어떤 형태의 파일이어도 저장할 수 있는 저장소
- AWS S3, Cloud storage에 파일 형태로 저장
- csv, parquet, json 등
- 별도로 DB나 Data Warehouse로 옮기는 작업 필요
- 이미지, 음성 등 저장
Data Warehouse에 저장하는 방식
- 여러 공간에 저장된 데이터를 한 곳으로 저장
- 데이터 창고
- RDBMS와 같은 SQL 사용하지만 성능 더 좋음
- AWS Redshift, GCP BigQuery, Snowflake
Python Logging
- Log Level

설정하지 않으면 warning보다 심각한 로그만 보여줌 - Python logging Module
#### 1. logging module 써보기 import logging logger = logging.getLogger("example") # getLogger() 메소드로 logger 객체 생성 logger.info("hello world") # 아무런 로그도 출력되지 않습니다. (warning 이상 아니라서) #### 1.1 logging module config 추가하기 import logging.config logger_config = { "version": 1, # required "disable_existing_loggers": True, # 다른 Logger를 overriding 합니다 "formatters": { "simple": {"format": "%(asctime)s | %(levelname)s - %(message)s"}, }, "handlers": { "console": { "level": "DEBUG", "class": "logging.StreamHandler", "formatter": "simple", } }, "loggers": {"example": {"level": "INFO", "handlers": ["console"]}}, } logging.config.dictConfig(logger_config) logger_with_config = logging.getLogger("example") logger_with_config.info("이제는 보이죠?")Logger
- 로그를 생성하는 Method 제공
- 로그 level과 filter 기반으로 처리해야 하는 로그인지 판단한다
- logging.getLogger(name)으로 Logger object 사용
- name이 주어지면 name의 logger 사용, name 없으면 root logger 사용
- logging.getLogger('foo.bar') -> logging.getLogger('foo')의 자식 logger 변환
- logging.setLevel(): Logger에서 사용할 level 지정
Handler
- Logger에서 만들어진 Log 전송
- Level과 Formatter 설정해서 필터링
- 종류: StreamHandler, FileHandler, HTTPHandler
Online Serving Logging (BigQuery)
JSON 형태로 저장하는 Logger
#### JSON Logging import logging from pythonjsonlogger import jsonlogger logger = logging.getLogger() logger.setLevel(logging.DEBUG) logHandler = logging.StreamHandler() formatter = jsonlogger.JsonFormatter() logHandler.setFormatter(formatter) # formatter 지정 logger.addHandler(logHandler) logger.info("hello world")BigQuery
- Goggle cloud platform의 데이터 Warehouse
- Apache Spark의 대용으로 활용 가능
- Firebase, Google Analytics 4와 연동하여 사용
- Dataset, Table, View 등
BigQuery 실시간 데이터 수집
- GCP Console BigQuery 접근 - 데이터세트 만들기
- 만들어진 데이터세트에서 테이블 생성 - 비용을 줄이기 위해 파티션 설정 가능
- BigQuery 데이터 로깅을 위해 서비스 계정 생성
- 만들어진 서비스 계정의 JSON key 다운로드
- JSON key로 파일을 읽고, 권한을 부여받을 수 있음
BigQuery Config.yaml 파일 구성
- simple: 일반 format
- json: json으로 로그 변환, (): logger config에서 사용할 클래스 지정
- pythonjsonlogger의 JsonFormatter 사용하면 텍스트 json으로 변환
- console handler: 기본 streamhandler 사용해서 터미널에 로그 출력
- logfile handler: 파일에 로그 저장
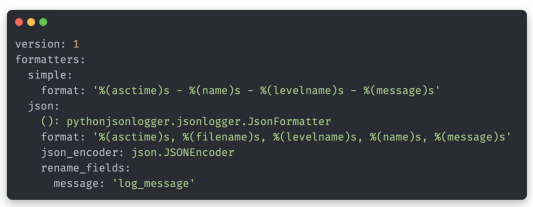

config.yaml BigQuery Logger.py 파일 구성
import json import logging.config import os from typing import Union from pydantic import BaseModel, BaseSettings, Field from datetime import datetime from logging import StreamHandler, LogRecord import pytz import yaml from google.cloud import bigquery from google.oauth2 import service_account from pythonjsonlogger import jsonlogger log_format = ", ".join( [ f"%({key})s" for key in sorted(["filename", "levelname", "name", "message", "created"]) ] ) class BigqueryLogSchema(BaseModel): level: str message: str created_at: datetime class BigqueryHandlerConfig(BaseSettings): credentials: service_account.Credentials table: Union[str, bigquery.TableReference] formatter: logging.Formatter = Field(default_factory=jsonlogger.JsonFormatter) level: int = Field(default=logging.INFO) class Config: arbitrary_types_allowed = True # pydantic 커스텀 클래스 사용 하기 위해 True class BigqueryHandler(StreamHandler):#streamHandler 상속받아 사용 def __init__(self, config: BigqueryHandlerConfig) -> None: super().__init__() self.config = config self.bigquery_client = bigquery.Client(credentials=self.config.credentials) self.setLevel(config.level) self.setFormatter(fmt=self.config.formatter) def emit(self, record: LogRecord) -> None: # BigQueryLogSchema 로그 형태에 맞게 파싱해서 데이터 가공 message = self.format(record) json_message = json.loads(message) log_input = BigqueryLogSchema( level=json_message["levelname"], message=json_message["message"], created_at=datetime.fromtimestamp( json_message["created"], tz=pytz.timezone("Asia/Seoul") ), ) errors = self.bigquery_client.insert_rows_json( # bigquery_client.insert_rows_json을 사용해 데이터를 실시간으로 저장 self.config.table, [json.loads(log_input.json())] ) if errors: print(errors) # 에러가 발생해도 Logging이 정상적으로 동작하게 하기 위해, 별도의 에러 핸들링을 추가하지 않습니다 # logger config를 기반으로 로그를 생성하는 함수 def get_ml_logger( config_path: Union[os.PathLike, str], credential_json_path: Union[os.PathLike, str], table_ref: Union[bigquery.TableReference, str], logger_name: str = "MLLogger", ) -> logging.Logger: """ MLLogger를 가져옵니다 Args: config_path: logger config YAML 파일의 경로 credential_json_path: service account json 파일 경로 table_ref: 로그가 저장될 빅쿼리의 table reference (e.g., project.dataset.table_name) logger_name: [optional] logger의 이름(default: MLLogger) Returns: logging.Logger: MLLogger """ # Default Logger Config를 추가합니다 with open(config_path, "r") as f: #config.yaml load해서 logging.config에 주입 logging_config = yaml.safe_load(f) logging.config.dictConfig(logging_config) _logger = logging.getLogger(logger_name) # BigQuery Logging Handler 추가합니다 if not credential_json_path: return _logger credentials = service_account.Credentials.from_service_account_file( filename=credential_json_path ) #bigquery handler 추가 bigquery_handler_config = BigqueryHandlerConfig( credentials=credentials, table=table_ref, formatter=jsonlogger.JsonFormatter(fmt=log_format), ) bigquery_handler = BigqueryHandler(config=bigquery_handler_config) _logger.addHandler(bigquery_handler) return _logger if __name__ == "__main__": from pathlib import Path here = Path(__file__) config_yaml_path = os.path.join(here.parent, "config.yaml") logger = get_ml_logger( # get_ml_logger 함수를 사용해서, 로그를 각 파일에, console에, bigquery에 저장 config_path=config_yaml_path, credential_json_path="C:/Users/yoonpyo/Downloads/concise-result-391608-6b110f009d56.json", # FIXME table_ref="concise-result-391608.online_serving_logs.mask_classification", # FIXME: e.g., boostcamp-ai-tech-serving.online_serving_logs.mask_classification ) for _ in range(10): logger.info("hello world") # hello world 10번 출력