-
최적화 (Optimization)CS 공부/AI 2023. 1. 11. 23:30
- Gradient Descent : 미분 가능한 함수의 극소값을 찾기 위한 1차 미분값 최적화 알고리즘
중요 용어
- Generalization: 일반화 성능, 학습데이터와 테스트 데이터에서 성능이 얼마나 차이가 나는지
- Overfitting: 학습데이터에서 잘 동작하지만 테스트 데이터에서 잘 동작하지 않음 (과적합)
- Underfitting: 네트워크가 너무 간단하거나 학습을 너무 조금시켜서 잘 동작하지 않음
- Cross-validation: 모델 유효성 검사 기법, 데이터를 나눠서 train, valid에 사용, 최적의 hyperparameter 찾는데 사용(test 데이터는 절대 쓰면 안됨)
- Variance: variance가 큰 모델은 비슷한 입력이 들어와도 출력이 많이 달라짐, variance가 낮으면 간단한 모델
- Bias: bias가 낮으면 원하는 값에 대부분 근사함, bias가 높으면 원하는 값과 많이 달라짐
- Bias and Variance Tradeoff: 학습 데이터에 noise가 있을 경우, bias와 variance는 둘다 낮거나 높을 수 없음, bias가 낮으면 variance가 높아짐
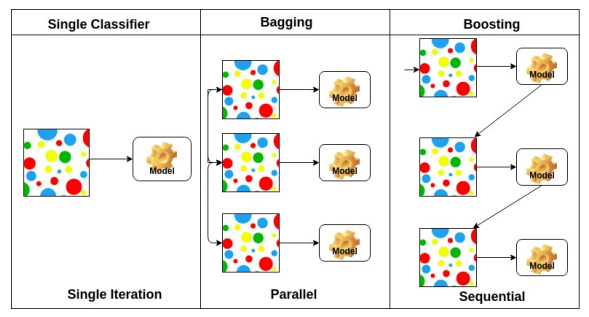
- Bootstrapping: 100개 데이터중 80개씩 무작위로 뽑아서 여러 모델을 만들어 돌렸을 때 얼마나 일치하는지 확인 -> 교체 시 무작위 샘플링을 사용하는 모든 metric
- Bagging: bootstrapping으로 훈련된 여러 모델, 랜덤 부분집합(투표 또는 평균)에 적합
- Boosting: 분류하기 어려운 특정 훈련 샘플에 사용, 이전의 weak learner를 sequential하게 합쳐서 strong learner(모델)을 만듦
Gradient Descent 방법
- Stochastic gradient descent: 하나의 샘플을 통해서 gradient 구해서 업데이트
- Mini-batch gardient descent: 데이터의 일부분에서 gradient 구함 (가장 많이 활용)
- Batch gradient descent: 전체 데이터에서 gradient 구해서 평균냄
- flat minimum은 train과 test 값의 차이가 별로 없지만 sharp minimum은 큼 → generalize performance가 떨어짐
경사하강법 적용하기
- Gradient Descent: learning rate 정하기 어려움, learning rate가 너무 크면 학습이 안되고 너무 작으면 학습을 아무리 시켜도 안됨

- Momentum : gradient가 왔다갔다 해도 학습이 잘됨, gradient 유지시켜줌

오래된 데이터일수록 현재의 경향에 미치는 영향이 줄어듦 더보기#python v = beta * v - learning_rate * gradient weight[i] += v- Nesterov Accelerated Gradient: 극소점에 더 빠르게 도달

모멘텀 스텝에 의해서 움직인 상태에서의 기울기 상태를 계산하여 이동함 - Adagrad: 학습 속도를 조정하여 매개 변수에 대한 더 큰 업데이트와 더 작은 업데이트를 수행 (조금 변한 파라미터는 많이 변화시키고, 많이 변한 파라미터는 조금 변화시킴)
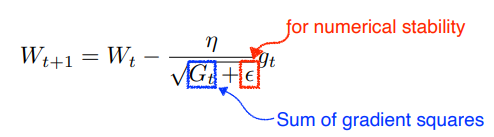
뒤로 가면 갈수록 학습이 멈춘다는 단점이 있음 - Adadelta: Adagrad의 확장 버전, accumulation window를 제한하여 단조롭게 감소하는 학습률을 줄임

learning rate가 없어 많이 활용 안됨 - RMSprop: 적응형 학습속도, 기울기 강하 속도를 증가시킴

Adadelta에서 step size(learning rate) 추가 더보기#python beta = beta * s + (1 - beta) * gradient**2 weight[i] += -learning_rate * gradient / (np.sqrt(s) + e)- Adam(Adaptive Moment Estimation): 과거의 gradient와 제곱 gradients를 둘다 사용
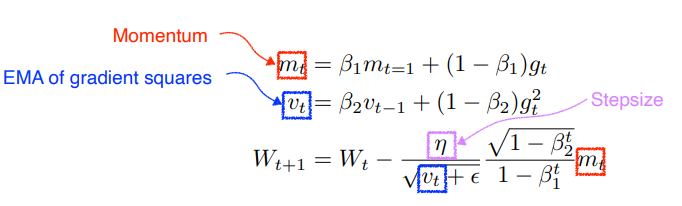
Momentum과 RMSprop을 효과적으로 결합 더보기# tensorflow2.x tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.99, epsilon=None)Regularization - Overfitting 완화 방법
- Early stopping: validation error가 커지기 전에 멈춤

validation error와 training error 차이가 커지기 전에 stop - Parameter Norm Penalty: parameter가 너무 커지지 않도록 함수의 공간을 더 부드럽게 함

- Data Augmentation: 데이터 증강, 각도를 회전시키거나 확대 축소 등..
- Noise Robustness: 노이즈를 신경망의 weight나 데이터에 추가
- Label Smoothing: 학습데이터 두개를 섞음 mixup- 강아지 고양이 곂치게 섞음, cutmix-사진 잘라서 합침

데이터가 한정적이거나 적을 때 사용 - Dropout: 일부 뉴런을 무작위로 0으로 설정
- Batch Normalization: 각 계층에 대해 경험적 평균과 분산을 독립적으로 계산하고 정규화
- L1 regularization: 기존의 cost function에 가중치의 크기가 포함되면서 가중치가 너무 크지 않은 방향으로 학습 되도록 함
- L2 regularization (Weight decay): 기존의 cost function에 가중치의 제곱을 포함하여 더함으로써 L1 Regularization 과 마찬가지로 가중치가 너무 크지 않은 방향으로 학습되게 된다
+ 지수 가중 평균 (Momentum & RMSprop)
[딥러닝]Optimization Algorithm (최적화 알고리즘)
Gradient Descent[경사하강법], Momentum[모멘텀], RMSprop, Adam, Learning rate decay[학습률 감쇠법]
velog.io
'CS 공부 > AI' 카테고리의 다른 글
CNN (0) 2023.01.12 Convolution 연산 (0) 2023.01.12 베이즈 통계학 (0) 2023.01.10 선형변환 (0) 2023.01.10 Neural network (0) 2023.01.09