-
GoogleNet, ResNetCS 공부/AI 2023. 3. 28. 22:14
네트워크를 깊게 쌓는 것이 항상 좋은 것은 아님!
기울기 소실, 계산 복잡도 상승, degradation 문제가 있음!
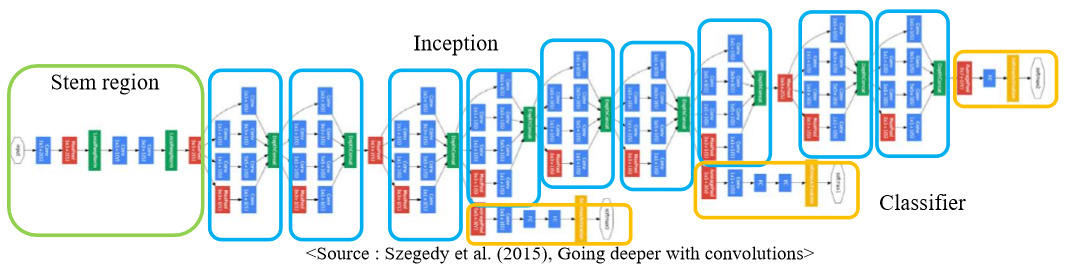
GoogleNet (2015)
- 모든 fillter 출력을 수평으로 연결 (concatenate)
- 하지만 이렇게 되면 계산 복잡도와 용량이 커져서 1x1 convolution을 적용하여 압축 (채널 수 조절, 계산량 감소)
- architecture
- vanilla convolution networks(stem region)
- stacked inception modules
- auxiliary classifiers
- 기울기 손실을 막기위해 중간중간에 넣어줌
- 하위 layers에 gradient 주입
- train할때만 사용하고 test시에는 사용 안함
- classifire output (FC layer 한개)
ResNet
- 네트워크를 더 깊이 쌓을수록 성능이 좋아진다는 것을 증명해낸 첫 모델
- 실험을 했는데 네트워크 깊이가 증가함에 따라 어느 순간 error가 더 감소하지 않았다
- overfitting 문제가 아니라 최적화의 문제다! 라고 결론내림
- 다른 Network는 단순히 Convolution 연산을 단순히 쌓는 반면, ResNet은 Block단위로 Parameter을 전달하기 전에 이전의 값을 더하는 방식이다
- Output에 이전 레이어에서 학습했던 정보 x를 연결함으로써 추가적으로 학습해야 할 정보 f(x)만을 Mapping
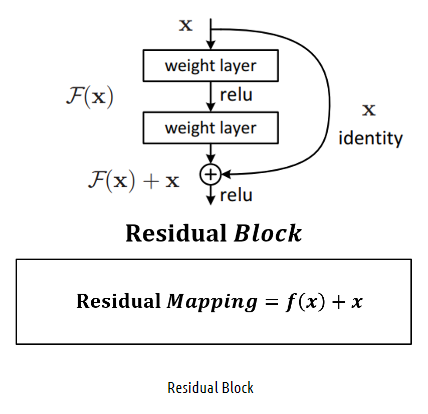
Residual block이 쌓이면 ResNet - Residual Mapping: weight layer들을 통과한 F(x)와 weight layer들을 통과하지 않은 x의 합
- shortcut connection으로 Overfitting, Vanishing Gradient 문제가 해결되어 성능이 향상됨
- Architecture (VGG-19 구조 기반)
- 7x7 Conv (He initialization) 1개
- residual block 여러개 쌓기 (모든 residual block은 2개의 3x3 conv를 가지고 conv layer 이후에 batch norm 수행)
- stride=2로 하여 매 block마다 down-sampling
- single FC layer

Beyond ResNets
DenseNet
- 각 layer의 모든 출력은 채널 축을 따라 수평으로 연결됨 (Resnet은 '+'로 신호를 합쳐버리지만 DenseNet은 보존)
- 상위 layer에서도 하위 layer 재참조
- gradient 소실 문제 완화, features 재사용
SENet
- Attention across channels
- Squeeze와 Excitation
- squeeze: global average pooling(W->1)을 통해 각 채널의 분포를 고정
- excitation: FC 계층에서 얻은 채널별 attention 가중치에 의한 채널 게이트 (중요한 것은 가중치 높이고 아닌 것은 낮추고)
EfficientNet
- 기존 모델은 모델의 깊이, 너비, 입력 이미지의 크기를 수동으로 조절했기 때문에, 최적의 성능과 효율을 얻지 못했다.
- EfficientNet은 이 세가지를 효율적으로 조절할 수 있는 compound scaling 방법을 제안
- 깊이, 너비, 입력 이미지 크기가 일정한 관계가 있다는 것을 실험적으로 찾아내고, 이 관계를 수식으로 만든 것
- 제일 좋은 architecture 중 하나
Deformable convolution (DCN)
- convolution 에서 사용하는 sampling grid 에 2D offset 을 더하는 방법
- 참고 블로그
[Object Detection] Deformable Convolutional Networks
Paper : https://arxiv.org/abs/1703.06211 Deformable Convolutional Networks Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in its building modules. In this work, we introd
eehoeskrap.tistory.com
요약

- AlexNet: 간단한 CNN 구조, 계산 시간 가장 빠름
- 높은 메모리 사이즈, 낮은 정확도
- VGGNet: 3x3 conv로 간단
- 메모리 사이즈 가장 큼, 계산 시간 가장 오래걸림
- GoogleNet: inception module, auxiliary classifier
- 가장 효율적인 CNN 모델이지만 너무 복잡함
- ResNet: 더 깊은 layers(residual blocks), 효율적
- 네트워크 구조 간단해서 가장 많이 씀
'CS 공부 > AI' 카테고리의 다른 글
📌 Two-stage detector(R-CNN)과 Single-stage detector(YOLO,SSD) (0) 2023.03.31 Semantic segmantation 모델: FCN, U-Net, DeepLab (0) 2023.03.30 Annotation data efficient learning (0) 2023.03.28 AlexNet과 VGGNet (feat. CNN) (0) 2023.03.28 Latent variable model (GAN, Diffusion model) (0) 2023.03.24