-
Semantic segmantation 모델: FCN, U-Net, DeepLabCS 공부/AI 2023. 3. 30. 04:24
Semantic segmantation란?
- 이미지의 픽셀 단위로 class 구분
- 의료 이미지, 자율주행, 컴퓨터 사진 기술에 활용
Fully Convolutional Networks (FCN)
- Semantic Segmentation 모델을 위해 기존 image classification에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)을 변형시킨 구조
- 호환성이 높음

- Convolution Layer를 통해 Feature 추출
- 1x1 Convolution Layer를 이용해 피처맵의 채널 수를 데이터셋 class 개수와 같게함
(Class Presence Heat Map 추출) - Up-sampling: 낮은 해상도의 Heat Map을 Upsampling한 뒤, 입력 이미지와 같은 크기의 Map 생성
- 최종 피처 맵과 라벨 피처맵의 차이를 이용하여 네트워크 학습
Semantic segmentation을 하기 위해 네트워크 뒷단에 fully connected layer 대신 fully convolutional layer을 붙여준다
- fully connected layer: 고정된 차원의 벡터를 출력하고 공간 좌표를 삭제
- fully convolutional layer(1x1 convolutions) : 공간 좌표가 있는 분류 map을 출력
- fully connected layer는 input의 크기가 고정되어있어, 모델에 들어가는 input size를 통일시켜줘야하고, 따라서 위치정보를 잃어버린다
- 1x1 conv layer는 상관없기 때문에 어떤 사이즈의 input도 가능하고, class의 score와 위치정보를 담고있는 heatmap을 얻을 수 있다
- 단점: score map의 해상도가 낮다... -> upsampling 방법을 사용하여 score map을 크게 만들었다!
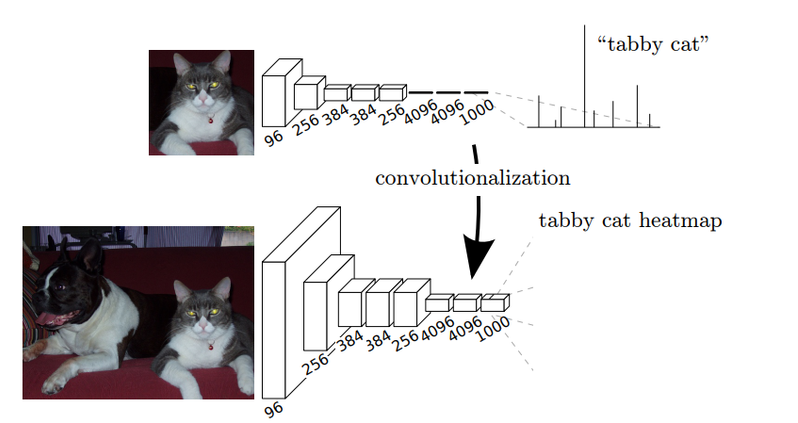
뒤의 3개의 Dense Layers가 모두 Conv-layer로 바뀜 Upsampling이란 무엇일까..?
- input 이미지의 크기가 더 작은 feature map으로 축소되는데 다시 input 이미지의 크기로 되돌리는 과정
- 두가지 대표적인 방법
- Transposed convolution (Deconvolution)
- 일반적인 conv layer와 다른 점은 input size가 output size보다 작다는 것이다
- 단점은 중첩되는 부분이 생기기 때문에 stride와 conv size를 잘 조절해야한다는 것,,
- Upsample and convolution
- Transposed convolution의 overlap 문제를 해결
- Nearest-neighber(NN), Bilinear 보간을 convolution 이후에 적용
- NN: Dense layer의 scale을 키우는데, 키운 위치에서 원본에서 가장 가까운 값을 그대로 적용하는 방법
- Bilinear: x, y의 2차원에 대해 선형 보간법을 통해 필요한 값을 채우는 방식
- Transposed convolution (Deconvolution)
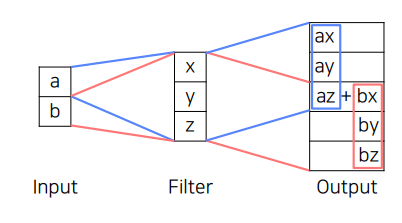

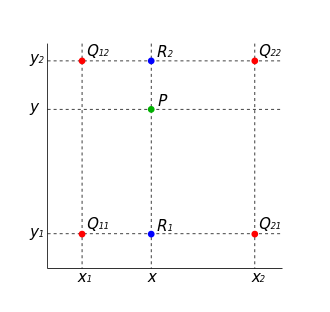
Deconvolution (중첩되는 부분을 더함), NN, Bilinear(R1이 Q11, Q21의 x축 방향 interpolation 결과, R2는 Q12, Q22의 x축 방향의 interpolation 결과) FCN 구조
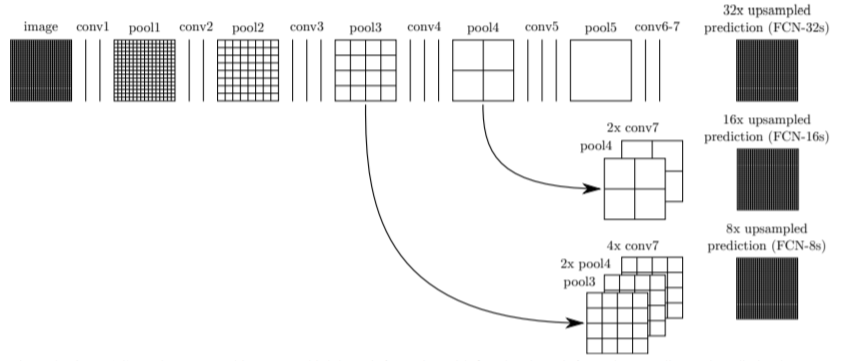
FCN-16은 pool4와 conv7으로만 이루어졌고, FCN-8은 pool3,4와 conv7로 이루어짐 성능은 FCN32<16<8 hypercolumns for object segmentation이라는 논문이 이와 동시에 나왔으나,,, FCN에게 패배했다는,,,한번 보면 좋을듯?
U-Net
- 영상의 일부분을 자세히 봐야할 때 자주 사용
- fully convolutional networks (FCN보다 좀 더 정교함)
- 구조1 (contracting path)
- Receptive field를 크게 확보하기 위해 해상도를 낮추고 채널 수를 늘림 (64->128)
- 3x3 convolution
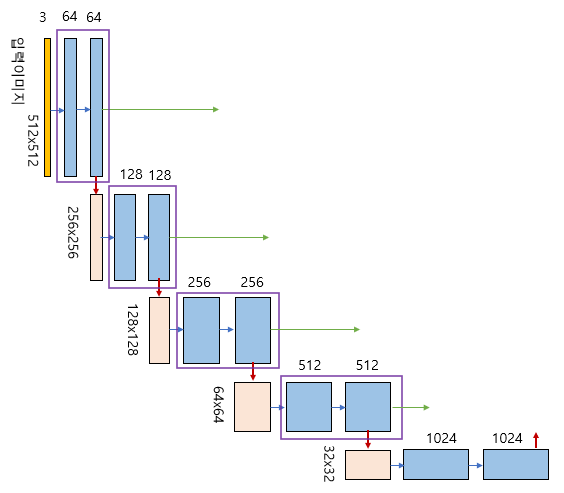
U-net의 contracting path (CNN과 동일) - 구조2 (expanding path)
- 해상도를 두 배 늘리고, 채널수는 반으로 줄임
- 2x2 convolution
- 두 개의 맵을 서로 합쳐서(concatenation) 저차원 이미지 정보뿐만 아니라 고차원 정보도 이용 가능
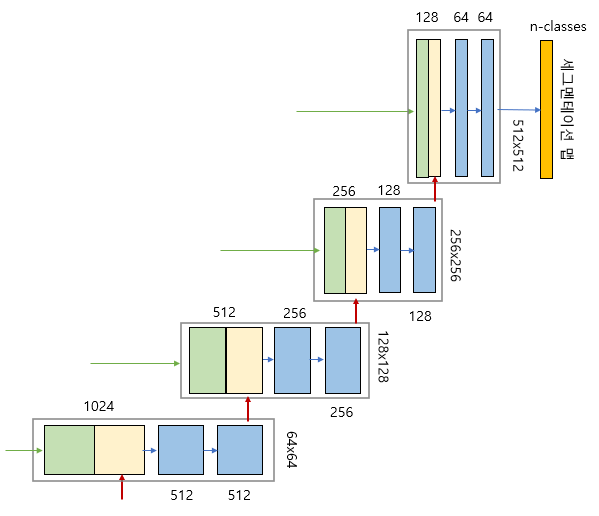
U-net의 expanding path - 7x7을 downsampling하면 버림되서 3x3이 되는데 이것을 다시 upsampling 하면 6x6이 되서 해상도 차이가 생김
- 따라서 feature map의 사이즈가 홀수가 되게 하면 안됨!!!
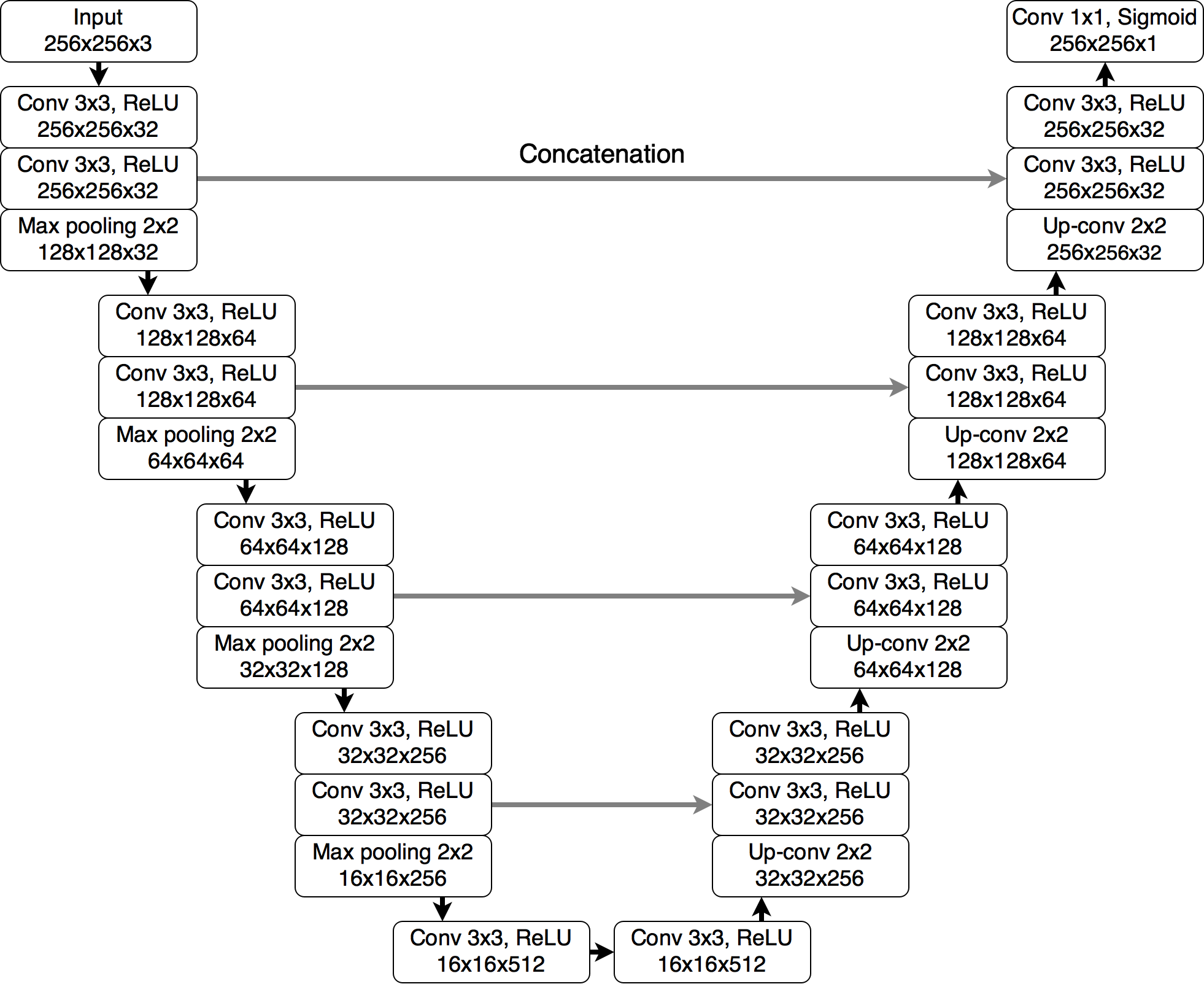
전체 구조 DeepLab 시리즈
Deeplab v1
- 부정확한 localization문제를 DCNNs의 마지막 레이어에서의 responses와 fully connected Conditional Random Field(CRF)를 결합하여 해결함
- CRFs로 후처리를 하는데, CRF를 반복할수록 정확도가 좋아진다

Deeplab v2
- Atrous convolution를 사용해 kernel 크기는 동일하게 유지하되, receptive field를 확장한다
- kernel 중간중간에 hole을 집어넣고 convolution 수행
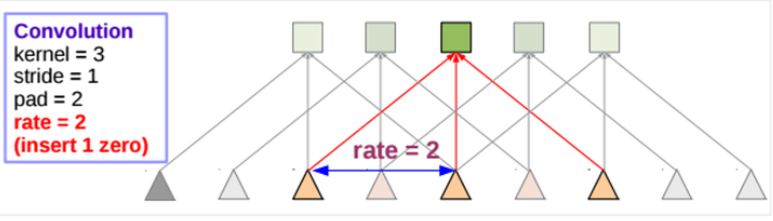
Deeplab v3
- Depthwise separable convolution (채널별로 convolution함)
Deeplab v3+
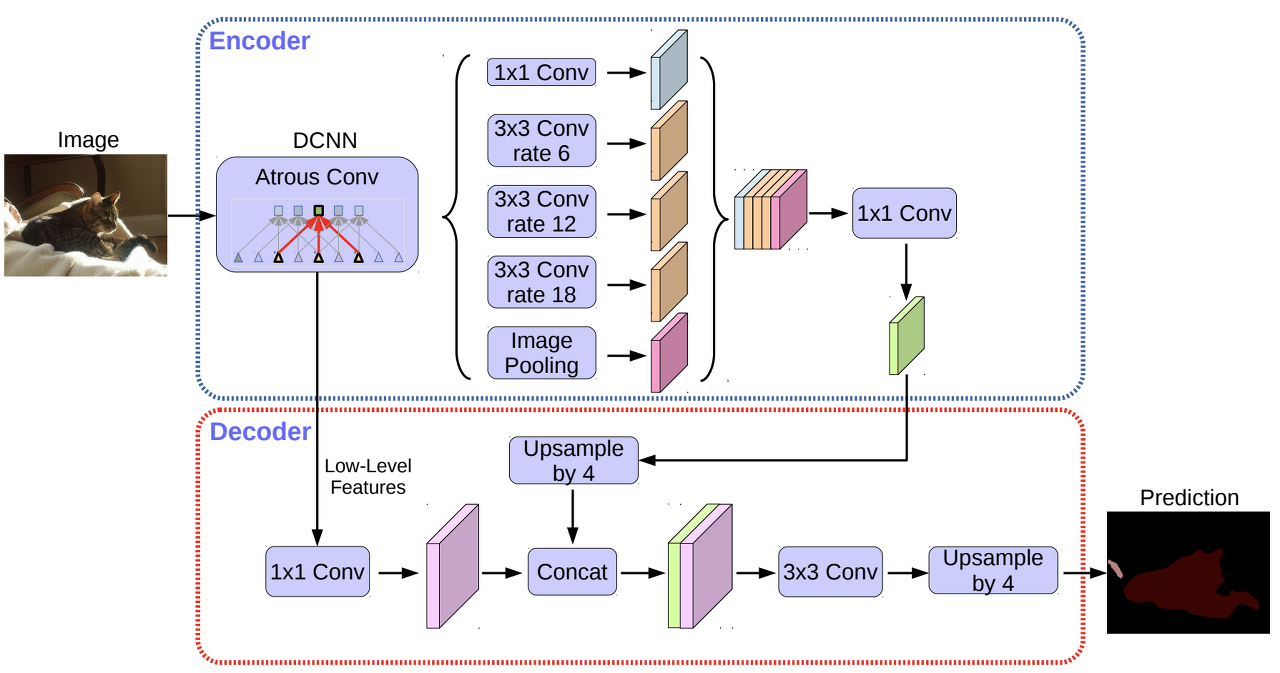
'CS 공부 > AI' 카테고리의 다른 글
CNN Visualization (결과 분석 기법) (0) 2023.04.03 📌 Two-stage detector(R-CNN)과 Single-stage detector(YOLO,SSD) (0) 2023.03.31 GoogleNet, ResNet (0) 2023.03.28 Annotation data efficient learning (0) 2023.03.28 AlexNet과 VGGNet (feat. CNN) (0) 2023.03.28