-
📌 Two-stage detector(R-CNN)과 Single-stage detector(YOLO,SSD)CS 공부/AI 2023. 3. 31. 21:17
Object detection
- Semantic segmentation: 객체 종류만 구분
- Instance segmentation과 Panoptic segmentation: 각각의 객체도 서로 구분 가능
- (P_class, x_min, y_min, x_max, y_max) : Classification + Box loacalization
- 자율주행, OCR 기술에 사용됨
- Two-stage와 Single-stage로 구분됨
Two-stage detector
초기의 방법들
- Gradient-based detector: 이미지/영상에서 각도에 따라 경계선 따서 객체 탐지
- Selective search
- Over-segmentation: 영상을 비슷한 색끼리 작게 분할
- 작게 분할된 영역들을 비슷한 색/ gradient끼리 합침
- 이렇게 해서 남은 segmantation에서 모든 bounding box 후보영역을 추출

Selective search R-CNN
- Selective search로 region proposal을 구함 (이미지에서 객체가 있을만한 영역만 추출)
- 적절한 사이즈로 warping한 뒤, fine-tuning된 CNN에 넣어줌
- CNN의 마지막 classifier 부분은 SVM을 사용
- 객체 분류
- 속도가 느리고, selective search와 같은 hand-crafted 기술을 사용하기 때문에 성능 향상에 한계가 있음
Fast R-CNN
- 원본 이미지에서 Convolution layer만 거친 feature map을 뽑음
- RoI Pooling 진행: feature map 재사용 할 수 있게
- R-CNN처럼 warp를 하면 이미지의 비율이 깨지는 등 원본의 정보가 소실되므로 이 문제 해결해줌
- feature map의 proposal region에서 정해놓은 크기의 grid를 이용해 격자의 bin안에 들어가는 값들끼리 maxpooling하여 고정된 크기의 feature를 만들어 냄.
- softmax와 bbox regressor 거쳐서 class와 box 예측
- 여전히 selective search의 한계,,
Faster R-CNN
- region proposal을 사용한 최초의 end-to-end object detection
- IIOU=(실제 box와 예측box의) 교집합 / 합집합
- Anchor boxes: 각 위치에서 발생할 것 같은 bbox를 미리 정의해놓은 것
IOU가 0.7이상이면 Positive, 이하면 Negative - Selective search로 시간 단축한 뒤 Region Proposal Network(RPN) 수행
- NMS 알고리즘으로 Bbox 추려냄
-
bbox 목록 중 C가 가장 높은 bbox 선택하고 목록에서 제거
-
C가 가장 높은 bbox와 나머지 bbox와의 IOU 계산하여 임계치보다 높으면 제거
-
두번째로 C가 높은 bbox와 1번~반복
-
목록에 bbox 없을 때까지 반복
-
R-CNN 계열 정리 Single-stage detector
정확도가 좀 떨어지더라도 실시간 obeject detection이 가능하도록 함
RoI pooling을 하지 않는 것이 특징
YOLO
- Bounding box 여러개와 confidence score, class probability map을 거쳐서 detection 수행
- 구조는 일반 CNN과 매우 유사
- 마지막 layer의 해상도에 의해서 SxS가 결정됨
- Real-time detector에서는 압도적인 성능
- Fast R-CNN보다는 정확도가 좀 떨어짐
SSD(Single Shot MultiBox Detector)
- yolo의 정확도 문제를 보완해줌
- 서로 다른 scale의 feature map을 예측에 사용하여 다양한 공간을 효과적으로 모델링할 수 있습니다
- anchor boxes가 8732개로 많지만, 구조가 단순해서 정확도가 높음 (Fast R-CNN보다 높음)
anchor boxes의 좌표정보=4 Single-stage detector의 단점 (Two-stage detector와 비교했을 때)
- RoI pooling이 없어 모든 영역의 loss가 계산됨
- 따라서 negative(없는데 있다고 하는것)한 anchor boxes가 positive한 anchor boxes보다 더 많음
해결책: Focal loss
- 정답일 경우에는 더 작은 loss를 갖고 오답일 경우에는 더 큰 loss를 갖게 함
- Easy Example의 weight를 줄이고 Hard Example의 weight를 키움
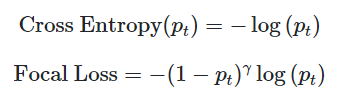
기존 cross entropy에서 식을 추가한 확장판 RetinaNet
- 새로운 loss function Focal loss를 처음 제안
- one-stage detector를 설계
- concatnate대신 (+)연산 수행
- 속도는 SSD와 비슷, 속도를 느리게하면 SSD보다 성능 좋음

- ResNet 기반의 FPN 사용하여 서로 다른 5개의 scale을 가진 feature pyramid net 출력
- 각 pyramid level별 feature map을 Classification subnetwork에 입력
- K=class개수, A=anchor box 개수
- channel 수가 KxA인 5개(feature pyramid의 수)의 feature map을 얻을 수 있다
- 각 pyramid level별 feature map을 Bounding box regression subnetwork에 입력
- anchor box별로 4개의 좌표값(x, y, w, h)을 encode하도록 channel 수를 조정
- 최종적으로 channel 수가 4xA인 5개의 feature map을 얻을 수 있다
DETR
- Transformer가 NLP에서 큰 성공을 거두자 Transformer을 CV에도 활용한 사례
- CNN Backbone + Transformer + FFN (Feed Forward Network)
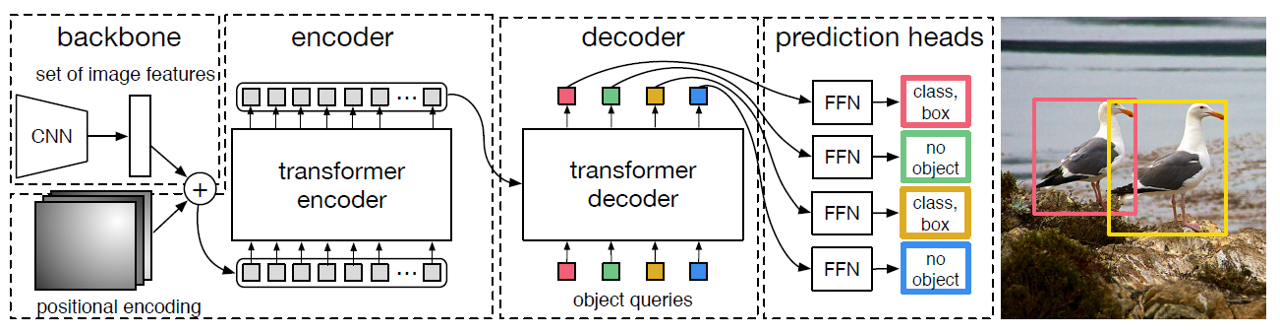
DETR 구조 (사진처럼 2개의 object만 존재한다면 2개의 bounding box에 대해서는 class, bounding box의 크기 및 위치를 예측하고, 나머지 2개에 대해서는 no object를 출력) 'CS 공부 > AI' 카테고리의 다른 글
📸 Instance/Panoptic segmentation + Landmark localization (0) 2023.04.04 CNN Visualization (결과 분석 기법) (0) 2023.04.03 Semantic segmantation 모델: FCN, U-Net, DeepLab (0) 2023.03.30 GoogleNet, ResNet (0) 2023.03.28 Annotation data efficient learning (0) 2023.03.28
